Apple Music's incoming Spatial Audio with Dolby Atmos and Lossless Audio features will be available in June on devices running iOS 14.6, iPadOS 14.6, macOS 11.4, and tvOS 14.6 or later, according to Apple.
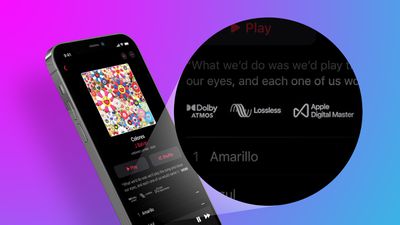
Apple said thousands of tracks will be available in Spatial Audio with Dolby Atmos at no additional cost, with more added regularly. Already available on the AirPods Pro, Apple describes Spatial Audio as an immersive three-dimensional audio format that enables musicians to mix music so it sounds like the instruments are all around you in space.
Apple Music subscribers will be able to listen to Dolby Atmos tracks using any headphones, according to Apple. When listening with AirPods or Beats headphones with an H1 or W1 chip, Dolby Atmos music plays back automatically when available for a song. For other headphones, users can go to Settings > Music > Audio and set Dolby Atmos to Always On.
Users will also be able to hear Dolby Atmos music using the built‑in speakers on a compatible iPhone, iPad, MacBook Pro, or HomePod, or by connecting an Apple TV 4K to a compatible TV or audiovisual receiver.
Apple Music is also getting two tiers of lossless audio at no additional cost, with more than 20 million tracks set to support the feature at launch and 75 million songs available by the end of the year. The standard "Lossless" tier refers to lossless audio up to 48kHz, while "Hi-Res Lossless" refers to lossless audio from 48kHz to 192kHz. "Hi-Res Lossless" will require a digital-to-analog converter, according to Apple.
Users will be able to turn on lossless audio in Settings > Music > Audio Quality.
iOS 14.6, iPadOS 14.6, macOS 11.4, and tvOS 14.6 are currently in beta. An exact launch date for the new Apple Music features was not announced.




















